

「社内の情報がどこにあるか分からない」「同じような質問が何度も寄せられる」「担当者によって回答が異なってしまう」
多くの企業で、このような課題が業務効率を低下させ、従業員のストレスを増大させています。デジタルトランスフォーメーション(DX)が加速する現代において、企業内に散在する膨大な知識、すなわち「ナレッジ」をいかに効率的に管理し、活用するかは、競争力を左右する重要な経営課題です。
これまでのナレッジベースは、情報を手動で整理し、ユーザーがキーワードで検索する仕組みが主流でした。しかし、この方法では「探すコスト」が高く、情報が古くなったり、そもそも必要な情報が登録されていなかったりと、形骸化してしまうケースも少なくありませんでした。
こうした状況を打破する解決策として今、大きな注目を集めているのが、生成AIを活用した「AIナレッジベース」です。ChatGPTに代表される大規模言語モデル(LLM)の進化により、従来の「検索型」から、自然な言葉で「対話」しながら答えを引き出す新しいナレッジ活用の形が現実のものとなりました。
本記事では、AIナレッジベース構築を検討している企業のDX推進担当者、情報システム部門、カスタマーサポート部門の責任者に向けて、その基本的な概念から、具体的な構築手順、ツールの選び方、運用のポイントまで、網羅的かつ実践的に解説します。この完全ガイドを最後まで読めば、自社に最適なAIナレッジベースを構築し、業務効率を飛躍的に向上させるための具体的な道筋が見えるはずです。
AIナレッジベースとは何か
まず初めに、AIナレッジベースがどのようなもので、従来の手法と何が違うのか、そしてどのような課題を解決できるのかを明確にしていきましょう。
AIナレッジベースの定義と従来型との違い
AIナレッジベースとは、人工知能(AI)と機械学習(ML)を活用して、企業内の膨大な情報を自動的に整理・分析し、ユーザーからの質問に対して最適な回答を自然な対話形式で提供する、一元化された知識のデータベース(ハブ)です。
従来のナレッジベースが、人間が手動で作成・整理した情報を保管する「静的な図書館」だとすれば、AIナレッジベースは、ユーザーの質問の意図を理解し、自ら情報を解釈して最適な答えを提示する「賢い司書」に例えることができます。
両者の違いを以下の表にまとめます。
| 比較項目 | 従来型ナレッジベース | AIナレッジベース |
|---|---|---|
| 情報検索 | キーワード検索 | 自然言語での対話・質問 |
| 回答形式 | 該当するドキュメントやFAQの提示 | 質問に対する直接的な要約・回答の生成 |
| コンテンツ管理 | 手動での作成・更新・整理 | AIによる自動的なコンテンツ生成・更新提案 |
| ユーザー体験 | 情報を「探す」手間がかかる | 対話を通じて「教えてもらう」感覚 |
| 学習能力 | なし | ユーザーとの対話から継続的に学習・改善 |
このように、AIナレッジベースは単なる情報の保管庫ではなく、ナレッジの活用方法そのものを変革するダイナミックなシステムであると言えます。
AIナレッジベースが解決する企業課題
AIナレッジベースは、多くの企業が抱える以下のような根深い課題を解決するポテンシャルを秘めています。
- 情報の散在と属人化:ファイルサーバー、社内Wiki、チャットツールなど、様々な場所に散らばった情報をAIが一元的に集約・整理します。これにより、特定の社員しか知らない「暗黙知」が形式知化され、組織全体の知識資産として活用できるようになります。
- 検索効率の低下:キーワードが一致しないと情報が見つからない、大量の検索結果から目的の情報を探すのに時間がかかるといった問題を解決します。AIが質問の文脈や意図を理解するため、ユーザーは探す手間なく、迅速に答えを得ることができます。
- 問い合わせ対応の負担増:社内ヘルプデスクやカスタマーサポートには、同じような質問が繰り返し寄せられる傾向があります。AIナレッジベースが一次対応を自動化することで、担当者はより専門的で複雑な業務に集中できるようになり、部署全体の生産性が向上します。
AIナレッジベースの主要な活用シーン
AIナレッジベースは、企業の様々な部門でその効果を発揮します。ここでは代表的な活用シーンをいくつか紹介します。
- カスタマーサポートの効率化:顧客からのよくある質問にAIが24時間365日自動で回答することで、顧客満足度の向上とサポート部門の負担軽減を両立します。オペレーターは、より複雑な問い合わせへの対応に集中できます。
- 社内FAQ・ヘルプデスクの自動化:情報システム部門や人事・総務部門への定型的な問い合わせ(例:「PCのセットアップ方法は?」「経費精算のルールは?」)にAIが対応。従業員の自己解決を促進し、バックオフィス部門の業務を効率化します。
- 営業支援・ナレッジ共有:製品情報、提案資料、成功事例、競合情報などをAIナレッジベースに集約。営業担当者は、顧客からの質問にその場で迅速かつ正確に回答できるようになり、提案の質を高めることができます。
- 新人教育・オンボーディング:新入社員が必要とする業務マニュアルや社内ルール、専門知識などをAIナレッジベースで提供。教育担当者の負担を減らしつつ、新入社員が自律的に学習できる環境を構築します。
AIナレッジベースの仕組みと主要技術
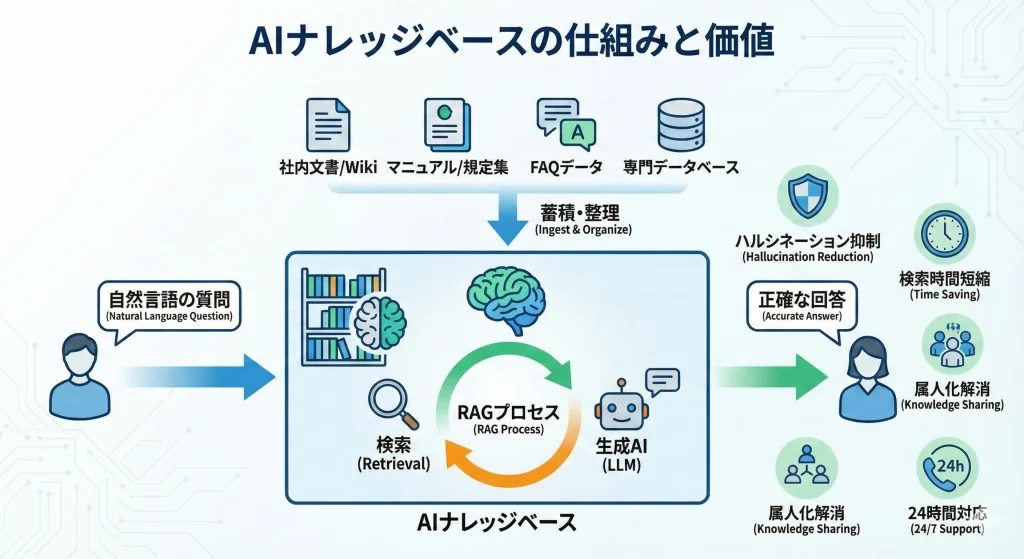
AIナレッジベースがなぜ自然な対話で最適な答えを導き出せるのか、その裏側にある技術的な仕組みを理解することは、適切なツール選定や効果的な運用のために不可欠です。この章では、AIナレッジベースを支える3つのコア技術と、特に重要な「RAG」「ベクトルデータベース」について解説します。
AIナレッジベースを支える技術要素
AIナレッジベースは、主に以下の3つの技術を組み合わせることで成り立っています。
- 自然言語処理(NLP: Natural Language Processing):人間が日常的に使う言葉(自然言語)をコンピューターが理解、解釈、生成できるようにするAI技術です。ユーザーからの質問の意図を汲み取ったり、膨大なドキュメントの内容を解析したりする際に中心的な役割を果たします。 [2]
- 機械学習(ML: Machine Learning):データからパターンを自動的に学習し、予測や判断を行う技術です。ユーザーの質問履歴やフィードバックを学習することで、AIは回答の精度を継続的に向上させることができます。どの情報がよく利用されるか、どの回答が問題解決に役立ったかを分析し、検索結果を最適化します。
- 大規模言語モデル(LLM: Large Language Model):ChatGPTのGPT-4やGoogleのGeminiのように、非常に大量のテキストデータでトレーニングされた言語モデルです。流暢で自然な文章を生成する能力に長けており、検索された情報をもとに、ユーザーへの回答を分かりやすく要約・生成する役割を担います。
RAG(Retrieval-Augmented Generation)とは
AIナレッジベースを構築する上で、現在最も重要視されている技術がRAG(Retrieval-Augmented Generation)です。日本語では「検索拡張生成」と訳されます。
RAGの基本的な仕組み
RAGは、LLMが回答を生成(Generation)する際に、あらかじめ社内データベースなどから関連性の高い情報を検索(Retrieval)し、その内容を根拠として回答を作成する仕組みです。これにより、LLMが学習していない社内固有の情報や、最新の情報に基づいた正確な回答が可能になります。
RAGは、外部データ(社内ナレッジなど)をAIの回答に取り入れる手法です。この方式により、「AIが勝手に創作する」のではなく、「企業内に存在する正確な情報をもとに回答する」仕組みが実現します。
なぜRAGが重要なのか
LLMは非常に高性能ですが、学習データに含まれていない情報や、学習時点以降の新しい情報については答えることができません。また、事実に基づかないもっともらしい嘘の情報を生成してしまう「ハルシネーション(幻覚)」という課題もあります。RAGは、これらのLLMの弱点を補い、回答の信頼性と正確性を担保するために不可欠な技術なのです。
RAGの処理フロー
- 質問受付:ユーザーが自然言語で質問を入力します。(例:「A製品の最新の納期は?」)
- 情報検索:システムはまず、質問に関連する情報を社内ナレッジベースから検索します。
- プロンプト生成:検索して見つかった情報(例:「A製品の納期は通常2週間だが、最新の通達では3週間に変更」)と元の質問を組み合わせ、LLMへの指示(プロンプト)を作成します。
- 回答生成:LLMは、与えられた情報に基づいて、質問に対する回答を生成します。
- 回答提示:生成された回答(例:「A製品の最新の納期は3週間です」)と、根拠となったドキュメントへのリンクなどをユーザーに提示します。
ベクトルデータベースの役割
RAGの「検索(Retrieval)」の精度を高めるために重要な役割を果たすのが、ベクトルデータベース(Vector Database)です。
ベクトル化と類似性検索
ベクトルデータベースは、テキストや画像などのデータを「ベクトル」と呼ばれる数値の配列に変換して保存します。ベクトル化することにより、単なるキーワードの一致不一致ではなく、意味の近さ(類似性)に基づいて情報を検索することが可能になります。
例えば、「自動車の価格」という検索クエリに対して、従来の検索では「自動車」「価格」という単語が含まれるドキュメントを探します。一方、ベクトル検索では、「クルマの値段」「車両の費用」といった、異なる単語でも意味的に類似した内容を含むドキュメントを見つけ出すことができます。
この類似性検索の能力が、ユーザーの曖昧な質問や多様な表現に対しても、関連性の高い情報を的確に見つけ出すRAGの性能を支えているのです。
主要なベクトルデータベース
代表的なベクトルデータベースには、Pinecone、Weaviate、Chroma、FAISSなどがあり、それぞれ特徴や得意な用途が異なります。ツールの選定にあたっては、データ量、求められる検索速度、クラウドかオンプレミスかといった要件に応じて最適なものを選択する必要があります。
AIナレッジベース構築のメリット
AIナレッジベースの導入は、単なるツール刷新にとどまらず、企業経営に多岐にわたるメリットをもたらします。ここでは、その効果を「業務効率化とコスト削減」「ユーザーエクスペリエンスの向上」「ナレッジの継続的な改善」という3つの側面に分けて解説します。
業務効率化とコスト削減
最も直接的で分かりやすいメリットは、業務効率の向上とそれに伴うコスト削減です。
- 検索時間の大幅短縮:従業員は、情報を探すためにファイルサーバーをさまよったり、同僚に質問して回ったりする必要がなくなります。必要な情報を即座に入手できることで、本来の業務に集中する時間が増え、組織全体の生産性が向上します。
- 問い合わせ対応の自動化:ヘルプデスクやカスタマーサポートに寄せられる定型的な問い合わせの多くをAIが自動で処理します。これにより、人件費を抑制しつつ、対応品質を維持・向上させることが可能です。
- 運用コストの削減:AIがコンテンツの不足や重複を自動で検出し、更新を提案するため、ナレッジベースのメンテナンスにかかる工数が大幅に削減されます。 [2]
ユーザーエクスペリエンスの向上
AIナレッジベースは、従業員や顧客といった「ユーザー」の体験価値を大きく向上させます。
- 24時間365日のセルフサービス:ユーザーは、時間や場所を問わず、必要な時にいつでも問題を自己解決できます。これにより、特に顧客満足度の向上に大きく貢献します。
- 自然な対話による情報取得:キーワードを考える必要なく、普段話すような言葉で質問できるため、ITツールに不慣れなユーザーでもストレスなく利用できます。
- パーソナライズされた回答:ユーザーの役職や過去の利用履歴に応じて、AIが最適な情報を提供することも可能です。これにより、一人ひとりのニーズに合わせたきめ細やかなサポートが実現します。
ナレッジの継続的な改善
AIナレッジベースは、一度構築したら終わりではありません。AIの学習能力によって、組織の成長とともにナレッジも進化し続けます。
- 自動的なコンテンツ更新:新たな問い合わせ内容や、解決に至った対話ログをAIが学習し、ナレッジベースに自動で追加・反映させることができます。これにより、情報は常に最新の状態に保たれます。
- 利用状況の分析と最適化:どのような情報が頻繁に検索されているか、どの回答が評価されているかをAIが分析。コンテンツの改善点や、新たに必要とされているナレッジを特定し、継続的な品質向上を促します。
- 知識の属人化防止:ベテラン社員の持つノウハウや暗黙知をAIとの対話を通じて形式知化し、組織全体の資産として蓄積・継承していくことができます。これにより、人材の流動化に対応できる強固な組織基盤が構築されます。
AIナレッジベースの構築手順【10ステップ】
AIナレッジベースの構築は、やみくもに進めると失敗に終わる可能性があります。ここでは、成功確率を高めるための実践的な手順を「準備」「設計」「構築」「運用」の4つのフェーズ、合計10のステップに分けて具体的に解説します。
準備フェーズ:成功の土台を築く
このフェーズでは、プロジェクトの方向性を定め、関係者の認識を合わせるための重要な準備を行います。
ステップ1:目的とターゲットユーザーの明確化
まず、「誰のために、何を解決するためにAIナレッジベースを導入するのか」という目的を具体的に定義します。例えば、「カスタマーサポート部門の問い合わせ対応工数を30%削減する」「全従業員が社内規定に関する疑問を3分以内に自己解決できるようにする」といった、定量的・定性的な目標を設定します。同時に、主な利用者(ターゲットユーザー)は誰なのか(例:顧客、新入社員、営業担当者)、彼らがどのような状況で、どのような情報を求めているのかをペルソナとして具体化します。
ステップ2:既存ナレッジの棚卸しと整理
次に、AIに学習させる元となる社内ナレッジが「どこに」「どのような形式で」「どの程度の品質で」存在しているかを洗い出します。ファイルサーバー内のWordやPDF、Excel、社内Wiki、チャットのログ、各種SaaSのデータなど、あらゆる情報源をリストアップします。この過程で、情報の重複、古い情報、誤った情報などを特定し、不要なデータをクレンジング(清掃)しておくことが、後のAIの回答精度を大きく左右します。
ステップ3:KPI・成果指標の設定
ステップ1で設定した目的に基づき、プロジェクトの成功を測定するための具体的な指標(KPI: Key Performance Indicator)を定めます。例えば、以下のような指標が考えられます。
- 業務効率:問い合わせ件数の削減率、一次回答率、平均回答時間
- ユーザー満足度:自己解決率、ユーザー満足度スコア、NPS(Net Promoter Score)
- コスト削減:サポートコストの削減額、運用工数の削減時間
これらのKPIを事前に設定しておくことで、導入後の効果測定や改善活動が的確に行えるようになります。
設計フェーズ:最適なシステムの青写真を描く
準備フェーズで定めた要件をもとに、システムの全体像を設計します。
ステップ4:ツール・技術スタックの選定
AIナレッジベースを実現するためのツールや技術を選定します。SaaS型のツールを利用するのか、オープンソースを組み合わせて自社で構築するのかを決定します。選定にあたっては、第5章で詳しく解説する「使いやすさ」「セキュリティ」「連携性」「コスト」などの観点から、複数の選択肢を比較検討します。この段階で無料トライアルなどを活用し、実際の使用感を確かめることが重要です。
ステップ5:データ構造とカテゴリ設計
ユーザーが情報を探しやすいように、ナレッジベース全体の構造を設計します。情報をどのようなカテゴリに分類し、どのようにタグ付けするかを定義します。優れた構造は、AIの検索精度を高めるだけでなく、ユーザーが直感的に情報をブラウズする際の手助けにもなります。
ステップ6:セキュリティ要件の定義
社内ナレッジには、機密情報や個人情報が含まれる場合があります。そのため、誰がどの情報にアクセスできるのかを制御するアクセスポリシーを厳密に定義する必要があります。「役職や部署に応じて閲覧範囲を制限する」「特定のIPアドレスからのみアクセスを許可する」といったセキュリティ要件を固め、選定するツールがそれを満たせるかを確認します。
構築フェーズ:システムを形にする
設計図に基づき、実際にシステムを構築していきます。
ステップ7:データ収集と前処理
ステップ2で棚卸ししたナレッジソースから、実際にデータを収集します。収集したデータは、AIが読み込めるように形式を統一し、不要な情報(ヘッダー、フッター、広告など)を削除する「前処理」を行います。この地道な作業が、AIの回答精度を直接的に左右する重要な工程です。
ステップ8:ベクトル化とデータベース構築
前処理したテキストデータを、ベクトルデータベースに投入して「ベクトル化」します。これにより、RAGの核となる意味の類似性に基づいた高速な検索が可能になります。この工程は、専門的なツールやライブラリ(例:LangChain, LlamaIndex)を利用することで効率化できます。
ステップ9:AIモデルの実装と統合
LLM(大規模言語モデル)をシステムに組み込み、RAGの仕組みを実装します。ユーザーからの質問を受け付け、ベクトルデータベースで検索し、得られた情報を基にLLMが回答を生成するという一連のワークフローを構築します。SaaSツールを利用する場合は、これらの機能がパッケージ化されているため、比較的容易に実装できます。
運用フェーズ:育て、改善し続ける
システムは構築して終わりではありません。継続的に改善していくことが成功の鍵です。
ステップ10:テスト・改善・継続的な最適化
本格導入の前に、一部のユーザーに限定してテスト利用してもらい、システムのパフォーマンスや使い勝手を評価します。AIが意図しない回答をしていないか、検索精度は十分かなどを検証し、ユーザーからのフィードバックを収集します。その結果を基に、AIモデルの微調整(ファインチューニング)やコンテンツの追加・修正を行い、継続的にシステムを改善・最適化していく運用体制を構築します。
AIナレッジベースツールの選び方
AIナレッジベースの構築プロジェクトにおいて、ツール選定は成否を分ける最も重要な意思決定の一つです。市場には多種多様なツールが存在するため、自社の目的や要件に合致した最適な選択をする必要があります。この章では、ツール選定で考慮すべき重要ポイントと、代表的なツールの比較を紹介します。
ツール選定の重要ポイント
ツールを選定する際には、機能の豊富さだけでなく、以下の4つのポイントを総合的に評価することが重要です。
- 使いやすさとUI/UX:最も重要なのは、ITの専門家でなくても、誰もが直感的に使えることです。管理画面でのコンテンツ登録・更新のしやすさ、そしてエンドユーザーにとっての検索や質問のしやすさ(UI/UX: ユーザーインターフェース/ユーザーエクスペリエンス)は、ツールの利用定着率に直結します。無料トライアル期間などを活用し、実際の操作感を必ず確認しましょう。
- セキュリティ対策:社内の機密情報や個人情報を扱う以上、セキュリティは最優先事項です。IPアドレス制限、二要素認証、シングルサインオン(SSO)連携、詳細なアクセス権限設定など、自社のセキュリティポリシーを満たす機能を備えているかを確認する必要があります。
- 既存システムとの連携性:ナレッジが散在している既存のシステム(例:Microsoft 365, Google Workspace, Slack, Salesforceなど)とスムーズに連携できるかは、データ収集の効率を大きく左右します。API連携の柔軟性や、標準で対応しているコネクタの種類を確認しましょう。
- コストパフォーマンス:初期導入費用だけでなく、月額利用料、ユーザー数に応じた課金体系、データ量による追加費用など、長期的な運用コスト(TCO: Total Cost of Ownership)を算出します。多機能で高価なツールが必ずしも最適とは限りません。自社の目的に必要な機能を過不足なく備え、投資対効果(ROI)が見込めるツールを選びましょう。
ツールのタイプ別分類
AIナレッジベースツールは、提供形態や特性によっていくつかのタイプに分類できます。自社の状況に合わせてどのタイプが適しているかを検討しましょう。
| 分類軸 | タイプA | タイプB |
|---|---|---|
| 提供形態 | クラウド(SaaS)型 | オンプレミス型 |
| サーバー管理不要で迅速に導入可能。 | 自社サーバーで運用。高いセキュリティとカスタマイズ性。 | |
| 機能範囲 | 特化型 | 汎用型 |
| カスタマーサポート、社内FAQなど特定の用途に最適化。 | 部門を問わず、様々な用途に柔軟に対応可能。 | |
| 導入形態 | ノーコード/ローコード型 | 開発者向け(カスタマイズ)型 |
| プログラミング不要で導入・運用が可能。 | APIやSDKを利用し、高度なカスタマイズやシステム連携が可能。 |
おすすめAIナレッジベースツール比較
ここでは、2025年現在、注目されている代表的なAIナレッジベース関連ツールを5つピックアップし、その特徴を比較します。
| ツール名 | 主な特徴 | タイプ | こんな企業におすすめ |
|---|---|---|---|
| Zendesk | カスタマーサポートの効率化に特化。強力なチケット管理システムとAIチャットボット、FAQサイト構築機能を統合的に提供。 | クラウド型/特化型 | 顧客対応の品質向上と効率化を目指すカスタマーサポート部門。 |
| Notion AI | 柔軟なドキュメント作成・共有機能が特徴の社内WikiツールにAIを統合。議事録の要約や文章作成支援など、ナレッジ生成の効率化に強み。 | クラウド型/汎用型 | ドキュメント中心のナレッジマネジメントを全社的に推進したい企業。 |
| Microsoft Viva | Microsoft 365に統合された従業員体験プラットフォーム。TeamsやSharePoint上の情報をAIが整理・提示し、従業員の学習や情報発見を支援。 | クラウド型/汎用型 | 既にMicrosoft 365を全社的に導入・活用している企業。 |
| Dify | LLMアプリケーション開発のためのオープンソースプラットフォーム。RAGパイプラインの構築やAIエージェント作成をGUIベースで柔軟に行える。 | オンプレミス可/開発者向け | 高度なカスタマイズや独自のAIアプリケーション開発を内製したい企業。 |
| NotebookLM | Googleが開発したリサーチ・ライティング支援ツール。アップロードしたドキュメントの内容に基づいてAIが質問応答や要約、アイデア出しを行う。 | クラウド型/汎用型 | 特定の資料群に関する深い分析や、レポート・論文執筆の効率化を図りたい個人・チーム。 |
この他にも、Guru、Starmind、Capacityなど、特定のニーズに特化した優れたツールが多数存在します。上記の比較表を参考に、自社の目的と要件を明確にした上で、複数のツールを候補として検討することをお勧めします。
AIナレッジベース構築の成功事例
理論や機能だけでなく、実際の導入企業がどのようにAIナレッジベースを活用し、どのような成果を上げているのかを知ることは、自社での活用をイメージする上で非常に有益です。ここでは、部門別の代表的な成功事例を紹介します。
カスタマーサポート部門での活用事例
ある大手ECサイト運営企業では、顧客からの問い合わせ件数の増加がサポート部門の大きな負担となっていました。そこで、ZendeskのようなAI搭載のカスタマーサービスプラットフォームを導入。過去の問い合わせデータとFAQコンテンツをAIに学習させ、AIチャットボットによる24時間対応のセルフサービスチャネルを構築しました。
成果:
- 問い合わせ件数の40%削減:定型的で簡単な質問はAIチャットボットが解決し、有人対応が必要な問い合わせ件数が大幅に減少しました。
- 顧客満足度の15%向上:顧客は待つことなく、いつでもすぐに回答を得られるようになり、顧客満足度調査のスコアが大きく向上しました。
- オペレーターの専門性向上:オペレーターは、クレーム対応や個別具体的な相談といった、より高度なスキルが求められる業務に集中できるようになり、従業員満足度も向上しました。
社内ヘルプデスクでの活用事例
従業員数1,000名を超える製造業のA社では、情報システム部門へのPC操作や社内システムに関する問い合わせが毎日100件以上寄せられ、コア業務を圧迫していました。Microsoft VivaとSharePointを連携させた社内向けAIナレッジベースを構築し、各種マニュアルや過去の問い合わせ履歴をAIに学習させました。
成果:
- 情報検索時間の80%短縮:従業員は、Teamsのチャット画面からAIに質問するだけで、膨大なマニュアルの中から必要な情報をピンポイントで探し出せるようになりました。
- ヘルプデスクの対応工数半減:同様の質問への繰り返し対応がなくなり、情報システム部門の担当者は、本来の業務であるシステム開発やインフラ改善に多くの時間を割けるようになりました。
- ナレッジの標準化:担当者の経験や知識に依存していた回答が標準化され、全社的に一貫した情報提供が可能になりました。
営業・マーケティング部門での活用事例
あるBtoBのSaaS企業では、製品の機能が多岐にわたり、営業担当者が顧客の専門的な質問に即座に答えられないことが課題でした。Notion AIを活用して、製品仕様書、技術ドキュメント、競合比較資料、過去の提案書などを一元化した営業ナレッジベースを構築しました。
成果:
- 提案品質の向上:営業担当者は、商談中にPCやスマートフォンからAIに質問し、技術的な仕様や導入事例をその場で正確に顧客へ提示できるようになりました。これにより、顧客からの信頼が高まり、受注率が向上しました。
- 新人営業の早期戦力化:OJTに時間がかかっていた新人でも、AIナレッジベースを活用することで、ベテラン社員と同様の知識レベルで顧客対応が可能になり、育成期間が大幅に短縮されました。
- マーケティング施策への活用:顧客からよく検索されるキーワードや質問内容を分析し、それを基にしたブログ記事やホワイトペーパーを作成するなど、コンテンツマーケティングの精度向上にも繋がっています。
AIナレッジベース運用の注意点とベストプラクティス
AIナレッジベースは導入して終わりではなく、継続的に育てていく「生き物」です。運用を成功させるためには、いくつかの注意点を理解し、ベストプラクティスを実践していく必要があります。
よくある失敗パターンと対策
- 失敗パターン1:コンテンツの質が低い
- 原因:AIに学習させる情報の精度が低い、情報が古い、内容が不十分。
- 対策:「Garbage In, Garbage Out(ゴミを入れるとゴミしか出てこない)」の原則を理解し、導入前にナレッジの棚卸しとクレンジングを徹底する。運用開始後も、定期的にコンテンツのレビューと更新を行う体制を構築する。
- 失敗パターン2:利用が定着しない
- 原因:ツールのUI/UXが悪い、回答精度が低く信頼されない、存在が知られていない。
- 対策:ツール選定時に使いやすさを最優先する。導入初期は回答精度が不安定なことをユーザーに周知し、フィードバックを積極的に収集して改善に繋げる。社内説明会や利用マニュアルの整備など、地道な利用促進活動を行う。
- 失敗パターン3:情報が古くなる
- 原因:コンテンツの更新・追加が特定の担当者に依存している、運用体制が不明確。
- 対策:各部門にコンテンツの責任者を任命し、情報の鮮度を保つためのワークフローを確立する。AIによるコンテンツ更新提案機能を活用し、メンテナンスの工数を削減する。
継続的な改善のポイント
AIナレッジベースの価値を最大化するためには、以下のサイクルを回し続けることが重要です。
- ユーザーフィードバックの収集:AIの回答に対する評価(「役に立った」「役に立たなかった」など)機能や、自由記述のフィードバックフォームを設置し、ユーザーの声を積極的に収集します。
- 利用状況の分析:管理ダッシュボードで、よく検索されるキーワード、解決率の高い質問、逆に解決に至らなかった質問などを定期的に分析します。これにより、ユーザーのニーズやコンテンツの課題が可視化されます。
- コンテンツの定期的な更新:分析結果に基づき、不足しているコンテンツを追加したり、分かりにくい記事を修正したりします。特に、解決率が低い質問は、優先的に改善対象とします。
セキュリティとプライバシーへの配慮
最後に、セキュリティとプライバシーは運用における最重要事項です。特に、クラウドベースのLLMを利用する場合は、機密情報や個人情報が意図せず外部に送信されないよう、細心の注意が必要です。
- 機密情報の取り扱い:個人情報や企業の経営に関わる重要情報は、マスキング処理(匿名化)を行うか、そもそもAIの学習対象から除外するなどの対策を検討します。
- アクセス権限の管理:従業員の役職や職務内容に応じて、アクセスできる情報の範囲を厳密に管理するポリシーを徹底します。
- データプライバシー規制への対応:GDPRや改正個人情報保護法など、国内外のデータプライバシーに関する法令を遵守した運用体制を構築します。
まとめ:AIナレッジベースで組織の知識を未来の力に
本記事では、AIナレッジベースの基本的な概念から、その仕組み、導入メリット、具体的な構築手順、そして運用に至るまで、包括的に解説してきました。
AIナレッジベースは、もはや一部の先進企業だけのものではありません。情報の散在、業務の属人化、問い合わせ対応の非効率といった、多くの企業が抱える普遍的な課題を解決し、組織全体の生産性を飛躍的に向上させる強力なソリューションです。
重要なのは、AIナレッジベースを単なる「ツール」としてではなく、組織の知識資産を育て、活用し続けるための「仕組み」として捉えることです。その成功の鍵は、明確な目的設定、質の高いデータ、そして継続的な改善サイクルにあります。
今後のトレンドとして、AIはさらに進化し、複数のシステムを横断して自律的に情報を収集・分析・実行する「AIエージェント」へと発展していくことが予想されます。AIナレッジベースの構築は、そうした未来に向けた重要な第一歩と言えるでしょう。
この記事を参考に、ぜひ自社の状況に合わせたAIナレッジベースの導入を検討し、組織に眠る無数の知識を、未来を切り拓く力へと変えてください。










